
by Sylvain Artois on May 26, 2025
In the first part, we set up a n8n pipeline to sync photos from my phone to a local Samba server, use a tiny CLIP-based microservice to filter out non-flower pictures, identify the flowers via the Pl@ntNet API, and store the results in Postgres.
This time, let’s build the second n8n workflow that picks up where the first one left off:
Both APIs have a generous free tier. I’m only posting on my personal Bluesky account, , so I’m not throwing money at this. The point is to stay focused on what matters: growing things in my garden, tracking blooming dates, and snapping the occasional decent shot.
Here’s the whole workflow — it might look like spaghetti at first, but don’t worry, we’ll untangle it. Under the hood, it’s all pretty chill:
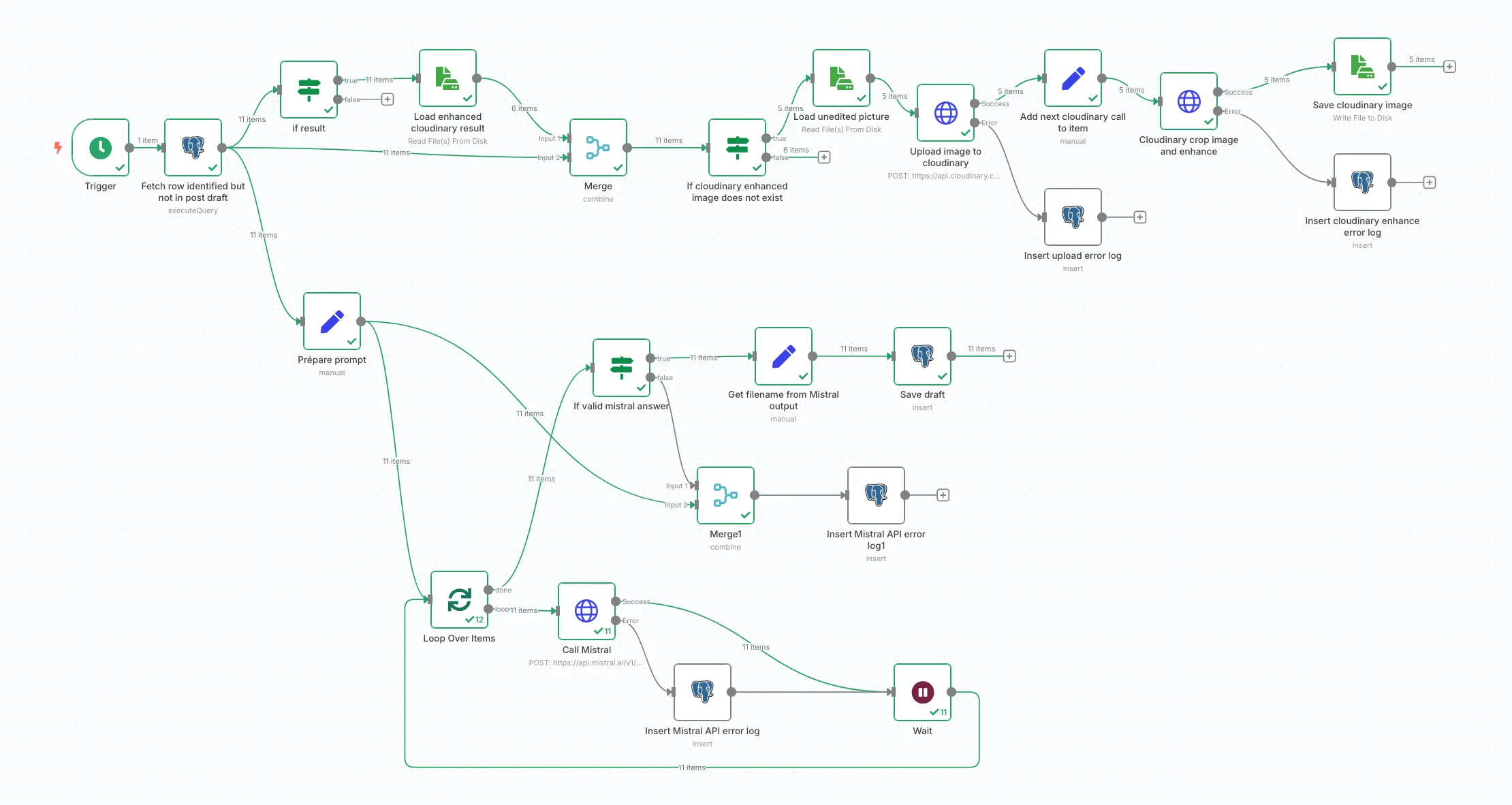
The trigger is a simple cronjob. From there, an SQL query fetches all flower photos that were successfully identified but haven’t yet made it into the “post_draft” table. The graph then splits into two totally independent subflows:
Cloudinary free tier is surprisingly generous:
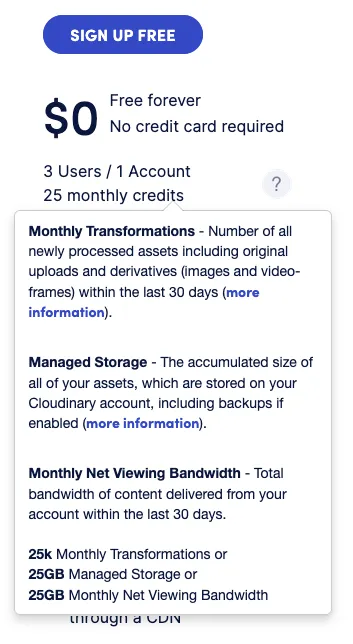
25,000 transformations per month? I’ll take it. The catch: AI-based transformations are way more expensive — like 100x more expensive for example with the enhance function which is interesting.
So the first part of this branch is just me trying to avoid burning through my quota. I don’t want to transform the same image twice for no reason.
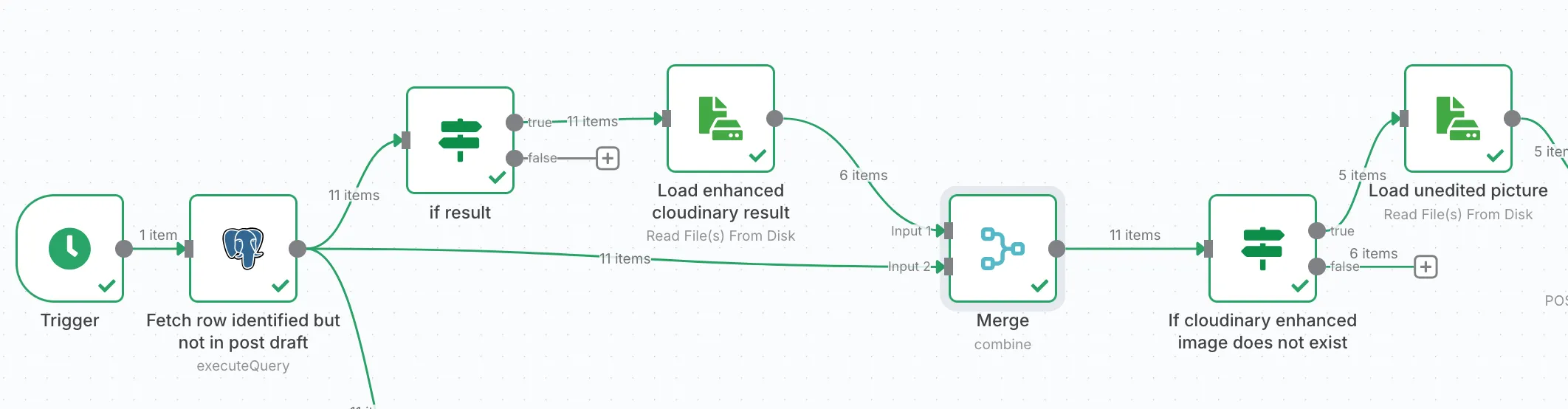
In plain English: if we need to generate a draft, we first check if the Cloudinary enhanced image already exists. If it does, we stop right there. If not, we grab the original — sitting on the shared Samba drive — and start the enhancement process.
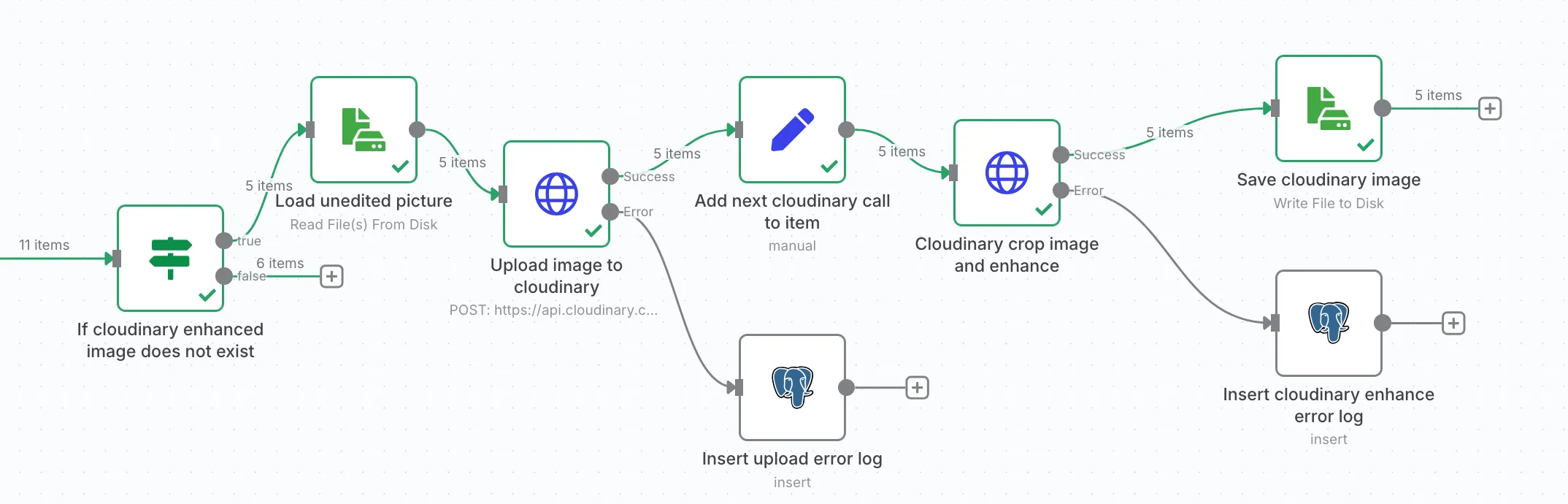
Now comes the fun part: we get to mess with Cloudinary’s API, which is honestly great. Their image transformations are super flexible.
First step: upload the image. Unfortunately, I couldn’t find a way to apply transformations directly on the fly without uploading first.
To upload properly, you’ll need to create an Upload Preset in their dashboard:
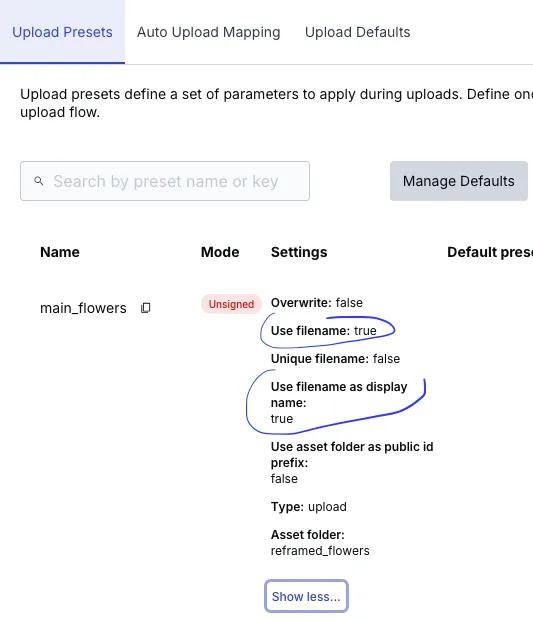
The game with n8n is preserving the required data from node to node. In my case, it’s the primary key, the original name of the image being processed. If I lose it after a node, I’m screwed for linking the node’s result with my information system. So here, by configuring Cloudinary to preserve my image name, I make things easier for myself in n8n. After upload, Cloudinary returns my image name, which I can then use to do a DB insert or whatever

Note: Cloudinary doesn’t have a built-in credential type in n8n. Just use the Generic Credential Type → Basic Auth → enter your API keys manually. Done.
n8n has a built-in error system at the workflow level, which is cool if you want Slack alerts or emails when something breaks.
But that’s not what I’m aiming for here. I want to catch HTTP errors, log them, and move on. No full-stop crashes. Let the other items keep flowing.
To do that, tweak the settings on your HTTP Request node. Change “On Error” to:
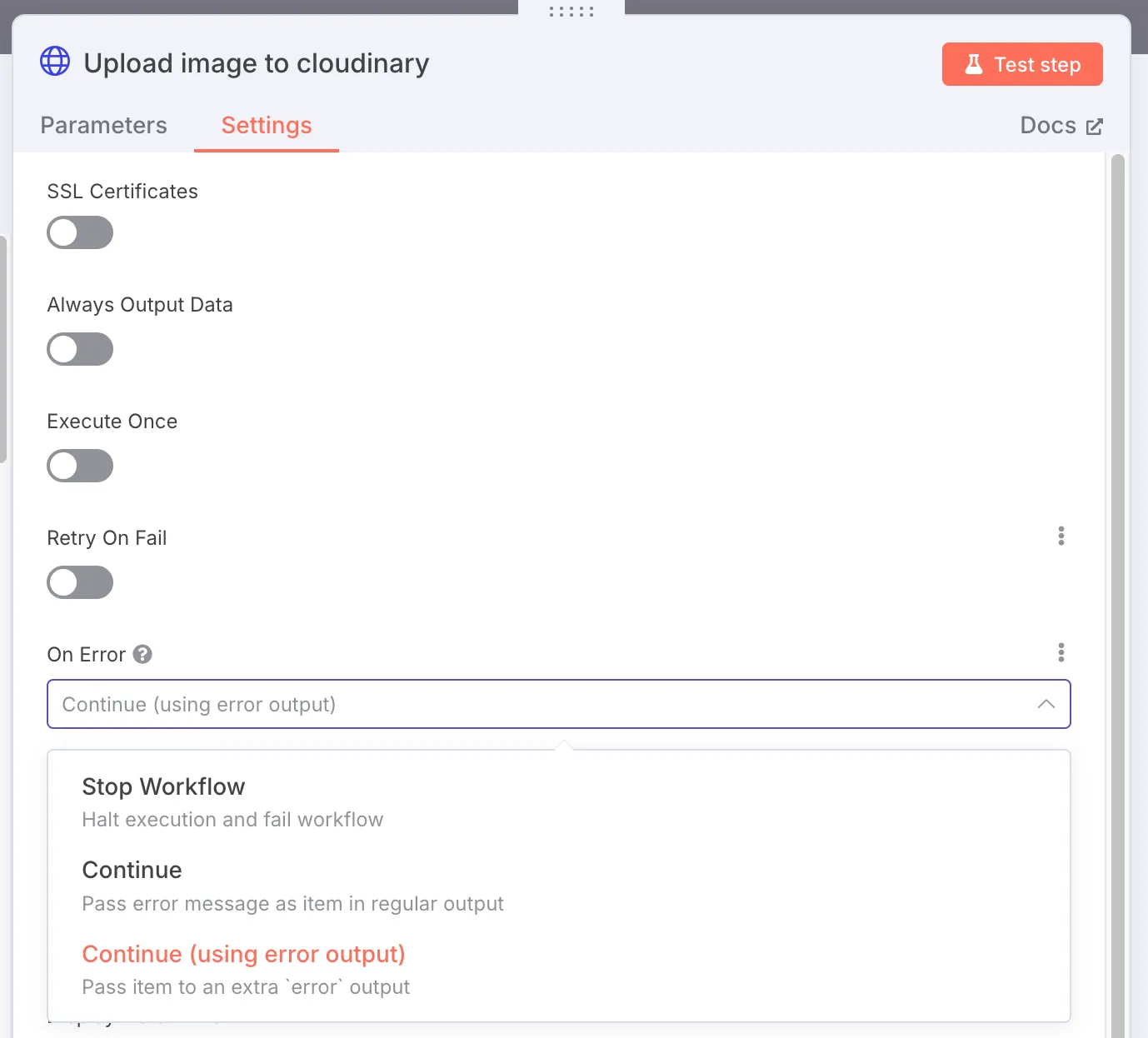
Now it’ll split into two branches: one for success, one for errors. That way you can log failures but keep processing the rest.
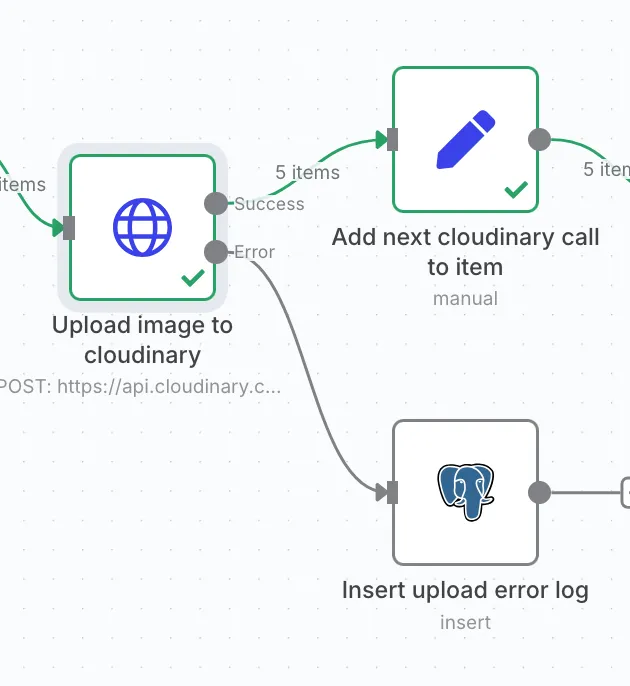
Once the image is uploaded, we move on to the transformation step.
I use an Edit Fields (Set) node to stash both the original upload info and the final transformation URL::
https://res.cloudinary.com/{{ cloud name }}/image/upload/c_fill,g_auto:subject,ar_1:1,w_500,q_auto/e_improve:60/{{ public_id }}.jpgHere I’m chaining 2 transformations sequentially (see the / between the two):
You crop first, then enhance. Doing it the other way around would mess with the lighting and contrast. Applying auto contrast to a whole image won’t have the same result as applying the same filter to part of that image.
The crop step:
subject parameter which activates deep learning; I could have passed classic to work with “simple” heuristics.Then e_improve:60 adjusts color, contrast and brightness, blending the original and filtered image for more natural results. The “60” is just the intensity
These are the parameters I chose initially, they’ll evolve - I think you need to play with the API and test the numerous settings.
And that’s the end of the branch: either the transformation fails (log it), or we save the new image.
Sometimes the result is… chef’s kiss:

Sometimes it’s an absolute disaster. Here we have a double failure: the photographer chose an aphid-eaten bluebell as his model, and the cropping software failed miserably:

But most of the time, it’s actually very good.
Here too, Mistral AI gives you a decent free tier. So far I’ve only hit one limit: one request per second.
n8n doesn’t care though — it blasts all items in parallel unless told otherwise. So if you’re processing a bunch of images, say goodbye to that rate limit.
Solution: throttle. Run the calls sequentially. Here’s what that branch looks like:
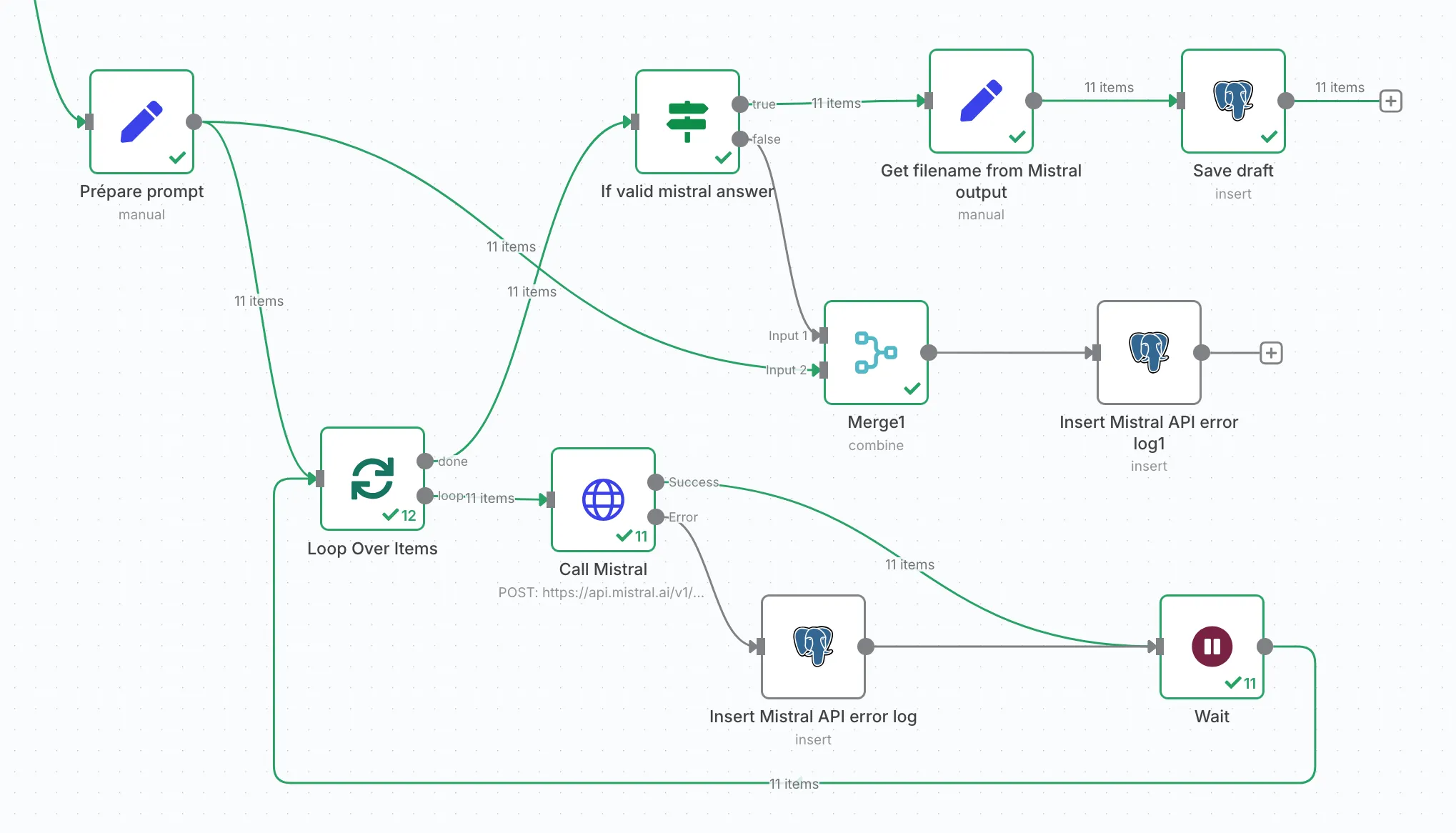
The prompt looks like this:
{
"model": "mistral-small-latest",
"messages": [
{
"role": "system",
"content": "You're a botanical poet."
},
{
"role": "user",
"content": "Here is an identified plant: {{ scientificName }} It can also be called {{ commonNames[0] }}. The photo was taken on {{ date_exif }} and the filename is {{ filename }}. Describe it in a poetic sentence, specifying the Latin name, the date the photo was taken, and the filename following this format: {{ filename }} | {{ date_exif }} - {{ scientificName }} Here a poetic sentence."
}
],
"temperature": 0.7,
"max_tokens": 1024,
"stream": false
}Yes, I’m relying on the LLM to follow a strict output format. Dangerous game. LLMs can hallucinate formats anytime. But here we are.
To respect the rate-limit, I use a “Loop over items” node. But here’s the catch: this node doesn’t merge outputs cleanly. So at the loop’s exit, I use a regex check to see if the filename is in the response:
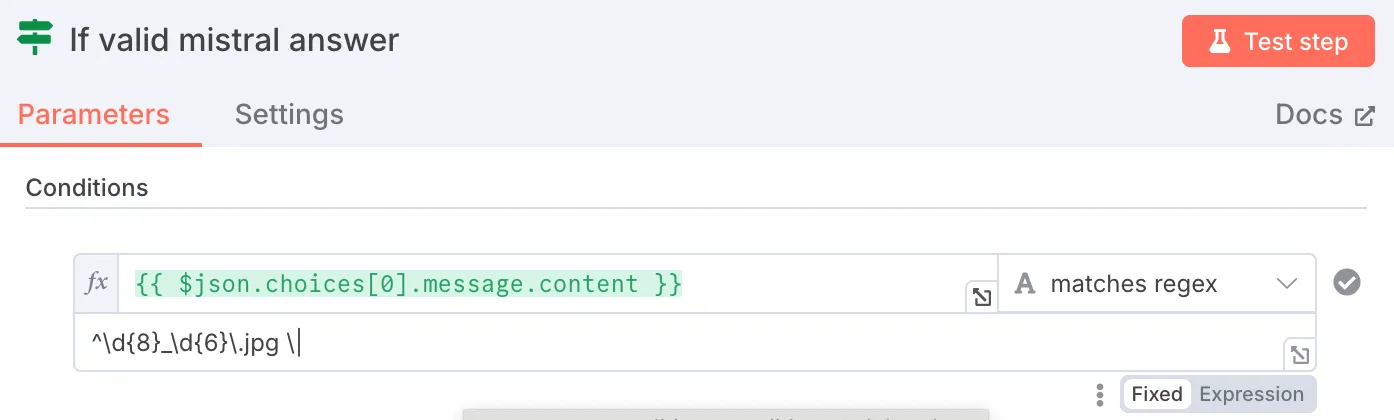
If not, I merge and log everything: filename, prompt, Mistral’s answer.
Honestly, the mistral-small model performed like a champ — out of about 100 test calls, not a single one messed up the format.
Example:
 2025/05/25 - Campanula persicifolia L. Under May’s sky, its white bells sing the ephemeral beauty of days.
2025/05/25 - Campanula persicifolia L. Under May’s sky, its white bells sing the ephemeral beauty of days.
Ideally, I wanted to go a step further: save the result as a scheduled draft somewhere. Spread out the posts. But I didn’t find a proper tool for that.
Social media tools are overpriced. Hootsuite? €99/month and doesn’t support Bluesky. Postpone offers a free tier, but limits to 5 posts per month, which is a bit low. Found not one but two Bluesky Schedulers and this other one, neither worked.
I could try Zapier or other no-code toys, but the issue isn’t automation — it’s editing. I want to preview, tweak the image, rewrite a line. You know, be human.
Maybe time to try Firebase Studio? With some vibe coding?
To be continued.